3 min læsning

Text is an indispensable helper when we make data visualizations, but we need to be careful not to let it steal the picture.
Quartz recently had a short article on the state of residential property prices around the world. The focus was on the wide disparities in price changes within each country between, on the one hand, the national average, and on the other hand, the prices in the largest city. The article suggests that generally, property prices tend to rise more in the largest city than in the given country as a whole. And that some anomalies can be spotted to that trend in recent figures - presumably the result of regional economic crises.
The article featured this visualization, making use of text, color, and position.
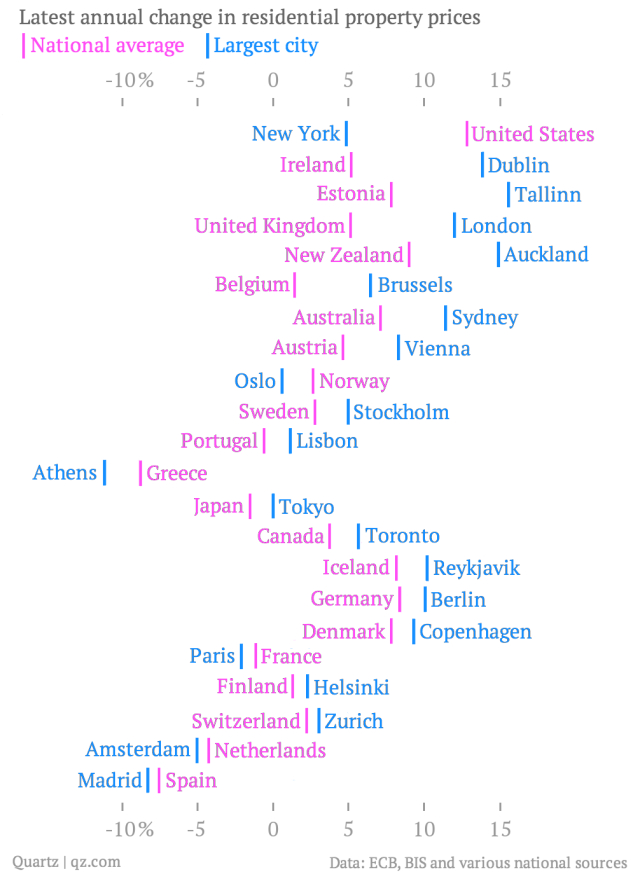
When looking at a visualization of quantifiable measures, I always search for patterns in the data. This one has an intriguing shape. It appears like two winding roads, intertwining and continuously widening and narrowing as the eyes travel down through the lines of text. Unfortunately, the pattern gets a bit distorted by the many text labels. The labels are clearly necessary for identifying the data points, but they ought to be supporting elements in a secondary role to the essence: the data points. Being as prominent as they are in the visualization, it takes some effort to identify the interesting anomalies (i.e. instances where pink exceeds blue) in the pattern. Notice also, how the longer text labels attract more attention than the shorter ones even though they are of equal importance - a problem we also see in 'word cloud' visualizations.
Let's do a little experiment to see if we can make the individual disparities and the anomalies stand out. We will use postion and length which are the most powerful means for visually encoding quantitative measures. Here, I should add that since I don't have the exact data, the values here are a quick read from the Quartz chart.
Initially, let's detach the labels from the data points. They are now placed in two columns at opposing sides of the graph. They no longer interfere with the data points, but the colors of the labels still clearly link them to their respective chart elements. Furthermore, by positioning the labels, we can easily single out points of interest. Next, we need to remeber that sorted data is a useful affordance in most data visualizations. In this one, for instance, it would save the reader the time and trouble of comparing and ranking all the countries. So let's sort the data by price increase for the largest city'.

Playing a little more, we can add bars to better show the magnitude of the difference between each set of price increases. At the same time, let's remove the dots and add the contour of the two 'winding roads' going through the countries.

OK - this was probably not the best idea (but sometimes you have to let creativity loose ). As Jason Karaian points out in the Quartz article, comparison between the countries is not straightforward, so we really ought to get rid of the bars. Like the chart below, where we are just showing the contours. The note that the data is not strictly comparable still applies, of course.
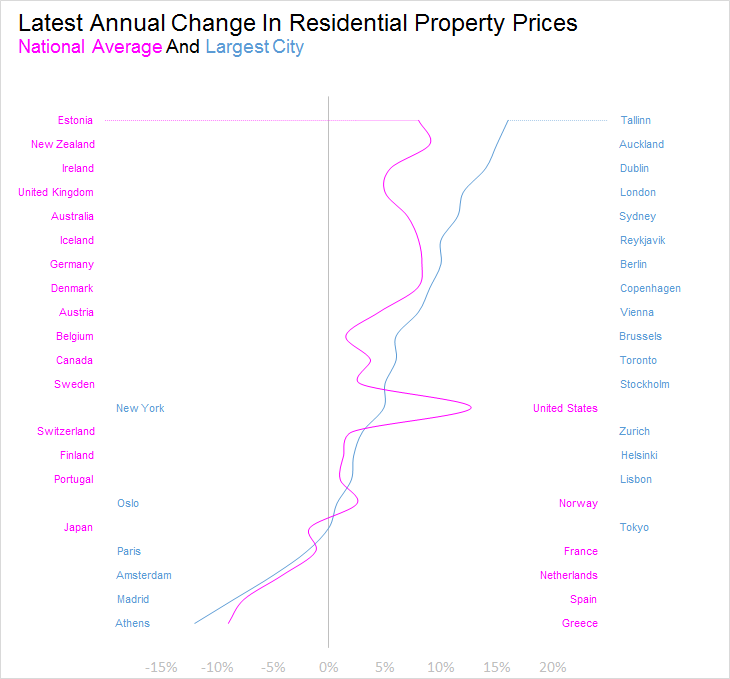
Improvement often is a question of small adjustments. Simply moving the labels out of the way while still letting them communicate through color and positioning sparked extra life into the visualization by enhancing the pattern.
Any questions?
Please reach out to info@inspari.dk or +45 70 24 56 55 if you have any questions. We are looking forward to hearing from you.
Relaterede Posts
Tired of crowded bars? The dot plot hits a sweet spot!
Seattle Seahawks use Azure to provide insights into the rehab process
Do more and keep winning just like the Seahawks with intelligent insights from #Azure.
This week,...